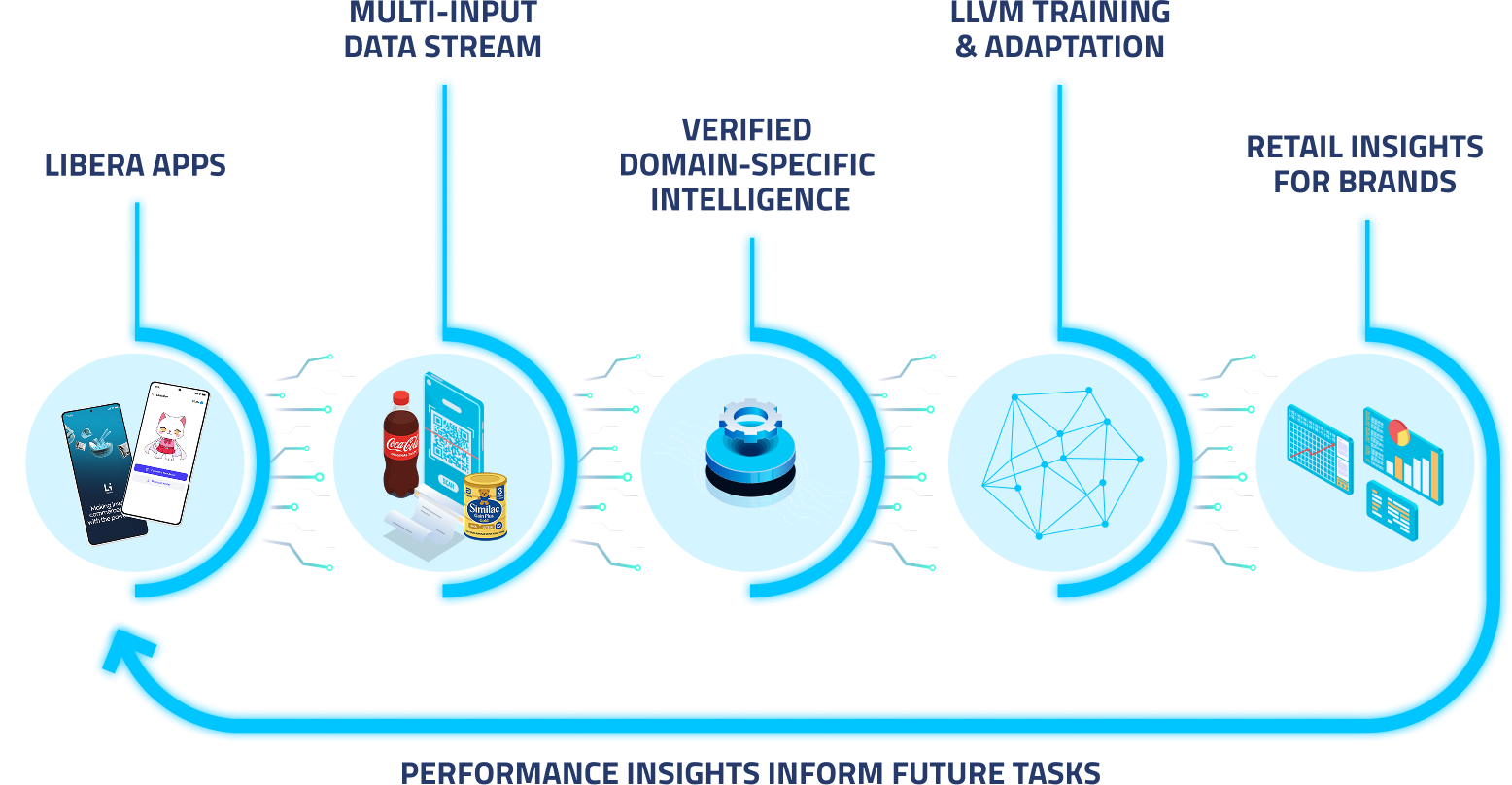
By linking real-time data from brands, merchants, and consumers, Libera creates a collaborative ecosystem that continuously fuels the Large Vision Model with decentralized, crowdsourced retail data.
This verified stream of domain-specific intelligence enables the model to learn, adapt, and improve—driving smarter insights, better shopping experiences, and increased profitability across the retail chain. Libera’s blockchain-powered reward system ensures transparent, equitable compensation for data contributors, while brands gain access to AI-curated intelligence—delivered at scale and in real time.